複数行あるファイルの読み込み
複数行あるファイルの読み込み操作は、いくつか方法があります。この記事では、1行読み込むごとに処理をする方法を紹介します。
※ファイルは前回の、str.txt を使用します。
[str.txt]
Hello! Hello! Good morning! Bye bye! Have a nice day! こんにちわ おはようございます。 バイバイ よい1日を!
ファイルの終端の判定にgetsコマンドを使う
次のサンプルは、単純にファイルから1行ずつ読み込んで画面に出力するプログラムです。ファイルの終端の判定にgetsコマンドを使います。
[サンプル] rw3.tcl
#!/bin/sh
# the next line restarts using tclsh \
exec tclsh "$0" "$@"
# ファイルから1行ずつ読み込んで画面に出力する
set fid [open str.txt r]
while {[gets $fid line] >= 0} {
puts $line
}
close $fid
[実行例]
$ ./rw3.tcl Hello! Hello! Good morning! Bye bye! Have a nice day! こんにちわ おはようございます。 バイバイ よい1日を!
上記のサンプルは、ファイルの終端を検出するまで1行ずつ読み込んで画面に出力しています。
詳しく説明すると次のような動作になります。
入出力チャネルは、現在参照している現在位置の情報を保持しています。
openコマンドの引数に「a, a+, APPEND」を指定すると現在位置は、ファイルの末尾に設定されます。それ以外はファイルの先頭に設定されます。
上のサンプルの場合は「r」をしているので、現在位置がファイルの先頭に位置づけされます。
そこからファイルを読み書きすると、処理したデータ分だけ現在位置が移動します。
次に、
gets $fid line
getsコマンドの第2引数に変数lineを指定しているので、読み込んだ文字列は変数lineに格納されます。戻り値は文字数を返します。
この書式のgetsコマンドはファイルの終端を検出すると戻り値は -1 を返します。
よって
while {[gets $fid line] >= 0} {puts $line}
は、getsコマンドが -1(終端検知) を返すまで、ファイルから文字列を1行ずつ読み出して、ループ本体を実行します。
getsコマンドの引数に変数を指定しない書式では、読み込んだ文字列を戻り値として返します。この場合、getsコマンドは、ファイルの終端に達すると空(カラ)文字を返します。
受け取った空文字は、空行を示すものなのか、ファイルの終端を示すものなのか判別することができません。
この場合、終端を判別するにはeofコマンドを使います。
*EOFはend of fileの略。
ファイルの終端の判定にeofコマンドを使う
以下はeofコマンドを使った場合の例です。
[サンプル] rw4.tcl
#!/bin/sh
# the next line restarts using tclsh \
exec tclsh "$0" "$@"
# ファイルから1行ずつ読み込んで画面に出力する。
# EOFコマンドを使用した例。
set fid [open str.txt r]
while {![eof $fid]} {
set line [gets $fid]
puts $line
}
close $fid
[実行例]
$ ./rw4.tcl Hello! Hello! Good morning! Bye bye! Have a nice day! こんにちわ おはようございます。 バイバイ よい1日を!
eofコマンドは、ファイルの終わりをチェックします。
例えば、getsコマンドで入力操作中に、ファイルの終端まで達している場合は、「1」を返します。そうでない場合は「0」を返します。
while {![eof $fid]} {…}
上の命令は、否定演算子を使用しているので、操作中の入出力チャネルをチェックしてファイルの終端に達するまでループ本体を実行します。
rw4.tcl を実行してみて何か変だ!と気が付いたでしょうか?
rw3.tcl の実行結果と比べると最後の行に空の行が1行余分に出力されています。
これは、getsコマンドの引数に変数を指定しない書式で記述しているので、ファイルの終端に達すると空文字を返すためです。
なぜ、rw4.tclのサンプルでは、空の行が1行余分に出力されるのかは、文字列の構造がどのようになっているか理解する必要があります。
文字列について
以下は、str.txtを16進ダンプしたものです。
[16進ダンプ]
$ hexdump str.txt -C 00000000 48 65 6c 6c 6f 21 20 48 65 6c 6c 6f 21 0a 47 6f |Hello! Hello!.Go| 00000010 6f 64 20 6d 6f 72 6e 69 6e 67 21 0a 42 79 65 20 |od morning!.Bye | 00000020 62 79 65 21 0a 48 61 76 65 20 61 20 6e 69 63 65 |bye!.Have a nice| 00000030 20 64 61 79 21 0a e3 81 93 e3 82 93 e3 81 ab e3 | day!...........| 00000040 81 a1 e3 82 8f 0a e3 81 8a e3 81 af e3 82 88 e3 |................| 00000050 81 86 e3 81 94 e3 81 96 e3 81 84 e3 81 be e3 81 |................| 00000060 99 e3 80 82 0a e3 83 90 e3 82 a4 e3 83 90 e3 82 |................| 00000070 a4 0a e3 82 88 e3 81 84 31 e6 97 a5 e3 82 92 ef |........1.......| 00000080 bc 81 0a 00 |...| 0a:\n:改行 00:\0:終端
下の図は 16進ダンプ を分かり易く文字列で表したものです。
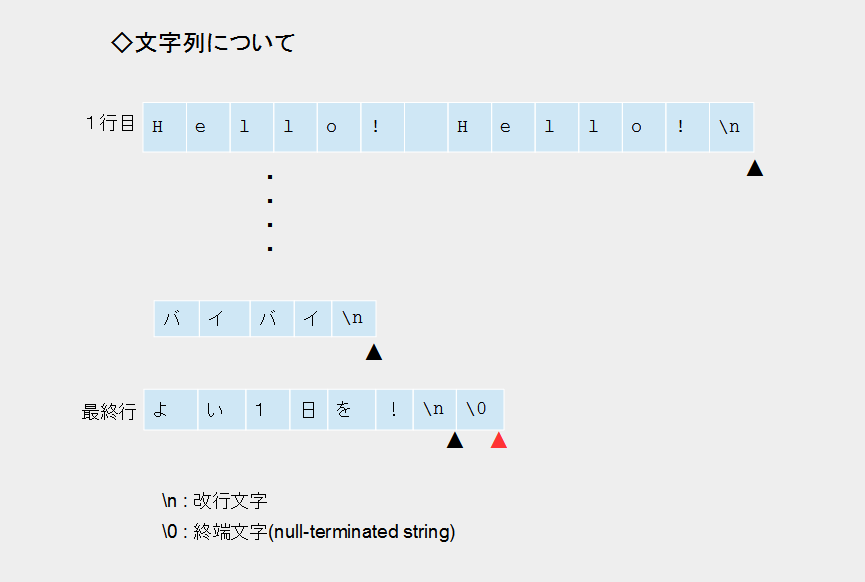
上の図を見てわかるように、最後の行以外は改行文字までが1行の文字列ですが、最後の行は、ヌル文字(null)になっています。
文字列は文字列の終端を示すために文字列の末尾にヌル文字(\0)を置きます。
よって、上の図の場合、1行目の Hello! の先頭から最後の行のヌル文字までが1つの文字列になります。
getsコマンドは、改行を含む1行を読み込んで、末尾の改行を削除した文字列を返します。ファイルの終端に達すると空文字を返します。
putsコマンドは、文字列に改行を付加して出力します。
rw4.tclを実行すると、最後の行は黒▲マークまで読み込みます。
この時点で参照しているファイルの現在位置は、最終行の黒▲マークの位置になります。
従ってこの後にeofコマンドで終端チェックをしても、終端と見なさないのでループ本体を実行します。
つまり最後の行を処理したあとに、さらにループ判定を行いループ本体を実行することになります。
ループ本体のgetsコマンドを実行すると、終端文字まで達している為、getsコマンドは空文字を返します。
次のputsコマンドは空文字に改行を付加して出力します。その結果、1行余分に出力されます。
リストや配列に1行1要素として代入を行い、各要素を順番に処理をするようなプログラムを考えた場合、rw4.tclのようなやり方をすると、空文字を余分に受け取ることになり、自分が想定した処理結果にならない可能性があるので注意が必要です。
これを回避するには、ループの入り口で終端をチェックするのではなく、getsコマンドで読み込んだ後、終端をチェックするようにします。
終端の判別にeofコマンドを使った例 その2
以下のサンプルは、getsコマンドで読み込んだ後、終端をチェックするようにした例です。
[サンプル] rw5.tcl
#!/bin/sh
# the next line restarts using tclsh \
exec tclsh "$0" "$@"
# ファイルから1行ずつ読み込んで画面に出力する。
# EOFコマンドを使用した例。その2
set fid [open str.txt r]
while {1} {
set line [gets $fid]
if {[eof $fid]} {
close $fid
break ;# ループを抜ける
}
puts $line
}
[実行例]
$ ./rw5.tcl Hello! Hello! Good morning! Bye bye! Have a nice day! こんにちわ おはようございます。 バイバイ よい1日を!
rw5.tclを実行すると最後に空行を出力しません。
[参考]
eof – Check for end of file condition on channel
次回は1行1要素としてリストに代入後、処理を行うプログラムを紹介します。