Tclの基本的なデータ構造として、変数、リスト、配列について紹介しましたが、これらの基本的なデータ構造を利用して、新しいデータ構造を作成する方法を紹介します。
レコード(Record)
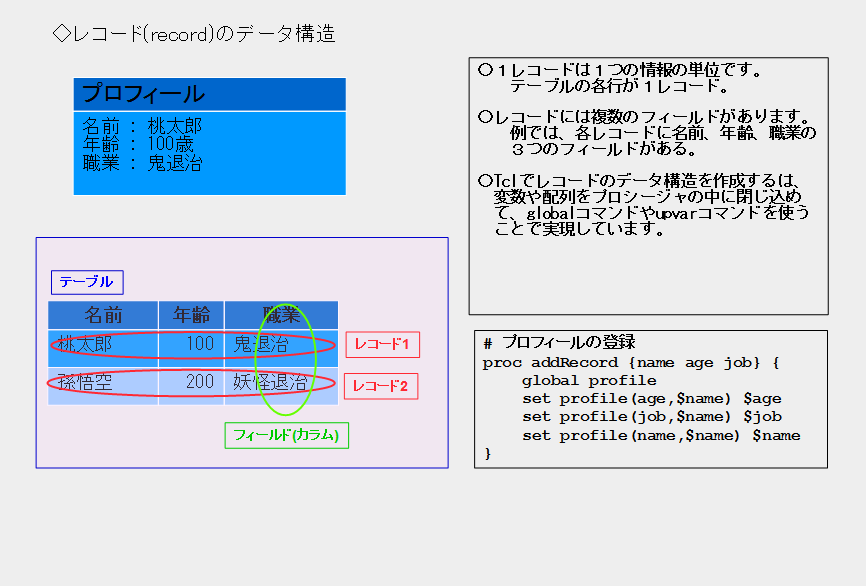
recordは日本語で「記録する」、「登録する」という意味があります。プログラミングにおいてレコード(record)とは、一連の変数をひとまとめにして1つのデータ構造を構築したものになります。
例えば、プロフィールやアドレス帳のように、会社名、部署、名前、住所、電話、E-mailといった複数の項目をひとまとめにして1つのレコードとして扱います。
他のプログラミング言語では、構造体(struct)やレコード型(record type)と呼ばれる複合データ型の変数を作成する機能がありますが、Tclにはありません。
Tclで同じようなデータ構造を作成するには、変数や配列をプロシージャの中に閉じ込めて、globalコマンドやupvarコマンドを使うことで実現しています。
[レコードのデータ構造のイメージ]
[サンプル] record.tcl
# レコードの作成
# プロフィールの登録
proc addRecord {id name age job} {
global profile
set profile(id,$name) $id
set profile(age,$name) $age
set profile(job,$name) $job
set profile(name,$id) $name
}
# IDから名前を検索
proc searchName {id} {
global profile
return profile(name,$id)
}
# プロフィールの紹介
proc profileList {name} {
upvar #0 profile p
puts "$name $p(age,$name) 歳 職業: $p(job,$name) でぇ~す。"
}[入力データ]
| ID | NAME | AGE | JOB |
|---|---|---|---|
| 001 | kirito | 16 | 剣士 |
| 002 | eren | 15 | 巨人退治 |
| 003 | c.c. | ? | 魔女 |
| 004 | miho | 16 | 戦車乗り |
[実行例]
% source record.tcl
# データ入力
% addRecord 001 kirito 16 剣士
kirito
% addRecord 002 eren 15 巨人退治
eren
% addRecord 003 c.c ? 魔女
c.c
% addRecord 004 miho 16 戦車乗り
miho
# IDから名前検索
% searchName 002
eren
# プロフィールの出力
% profileList eren
eren 15 歳 職業: 巨人退治 でぇ~す。
% profileList miho
miho 16 歳 職業: 戦車乗り でぇ~す。
% parray profile
profile(age,c.c) = ?
profile(age,eren) = 15
profile(age,kirito) = 16
profile(age,miho) = 16
profile(id,c.c) = 003
profile(id,eren) = 002
profile(id,kirito) = 001
profile(id,miho) = 004
profile(job,c.c) = 魔女
profile(job,eren) = 巨人退治
profile(job,kirito) = 剣士
profile(job,miho) = 戦車乗り
profile(name,001) = kirito
profile(name,002) = eren
profile(name,003) = c.c
profile(name,004) = miho
addRecordの最後に記述している「set profile(name,$id) $name」は、配列のキーを「profile(name,$name)」としても構わないのですが、IDを検索キーとして使用できるようにしています。
上のサンプルは単純にTclの配列でレコード構造を実装した例です。名前からID、名前から職業といった検索が必要な場合、その処理も必要になってきます。
スタック(Stack)
stackは日本語で「積み重ねる」という意味があります。プログラミングにおいてスタックとは、要素の挿入と削除がデータ列の先頭だけで行われるデータ構造をしたものです。
ちょうど積み重ねた本をイメージするとわかりやすいと思います。本を積み重ねる場合、一番上の位置に順番に積み重ねていき、取り出す時も一番上から順番に取り出しますよね。
このような構造のことを、LIFO (Last In, First Out) と呼ばれています。LIFOは、「後入れ先出し」とも言われ、最後に入れたものを最初に取り出すデータ構造をしています。
[スタックのイメージ]
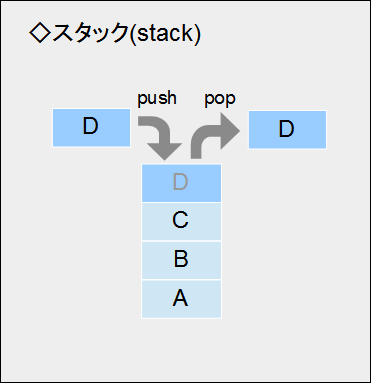
スタックに要素を挿入する操作を「push」、要素を取り出す(削除する)操作を「pop」と言います。
スタックは、テキストエディタの「元に戻す(undo)」や、ブラウザの「戻る(back)」ボタンなどで利用されています。
スタックをTclのリストで実装すると以下のようになります。
[サンプル] stack.tcl
# スタックの作成
proc push {stack data} {
upvar $stack lst
lappend lst $data
}
proc pop {stack} {
upvar $stack lst
set data [lindex $lst end] ;# 最後の要素の取り出し
set lst [lrange $lst 0 end-1] ;# 最後の要素を削除
return $data
}[実行例]
% source stack.tcl
% set stack ""
# a1~d1を挿入
% push stack a1
a1
% push stack b1
a1 b1
% push stack c1
a1 b1 c1
% push stack d1
a1 b1 c1 d1
# d1,c1を取り出し
% pop stack
d1
% pop stack
c1
# c2,d2を挿入
% push stack c2
a1 b1 c2
% push stack d2
a1 b1 c2 d2
上のサンプルは、単純にTclのリストでスタックを実装した例です。
スタックオーバフローというメッセージを聞いたことがありますか?
スタックオーバフローとはスタックの容量を超えて挿入しようとした時に出力するメッセージです。上のサンプルはスタックの容量は考慮していないので、いくらでも積み重ねできます。
スタックの容量を指定する必要がある場合は、容量を指定する処理も必要です。例えば、元に戻す最大回数を20回までにするなど。
この場合、指定回数を超えたら、
- 一杯であることを通知する。
- 古いデータから消していく。
- 最後の要素のみ上書きする。
などの処理が必要になってきます。
よって、実際のプログラムでは、オーバフロー(満杯のスタックにpush)、アンダーフロー(空のスタックにpop)した時の処理も必要になってきます。
キュー(queue)
queueは日本語で「待ち行列」という意味があります。プログラミングにおいてキュー(queue)とは、データ列に最初に挿入した要素から順番に取り出すデータ構造をしたものです。
キューのイメージは、お店のレジで人が並んでいる様子をイメージするとわかりやすいと思います。レジに並んだ人から順番にレジで精算をしていきますよね。
このような構造のことを、FIFO(First In, First Out)と呼ばれています。FIFOは、「先入れ先出し」とも言われ、最初に入れたものを最初に取り出すデータ構造をしています。
[キューのイメージ]

要素をキューの末尾に追加する操作を「エンキュー(enqueue)」、キューの先頭から要素を取り出す操作を「デキュー(dequeue)」と言います。
キューは、順番に実行する必要がある処理で利用されます。
例.
- 複数の印刷データを順番にプリンタへ出力する。
- バックアップ、集計などのバッチ処理を順番に実行する。
Tclでキューを実装する場合、以下の3つの方法が考えられます。
- デキュー実行後、先頭の要素を削除する。
- デキュー実行後、先頭の要素は削除せずに、先頭位置を移動させる。
- リング状のデータ構造を作る。
Tclのリストは空白区切りの単なる文字列ですが、他の言語では、各要素が別々の箱になっています。よって 他の言語で、1 のやり方をすると、各要素の値を移動させる必要が生じます。
このようなことから、キューの実装方法は、2 または 3 で説明していることがほとんどです。
1,2,3をTclのリストで実装すると以下のようになります。
1.デキュー実行後、先頭の要素を削除する

[サンプル] queue1.tcl
#!/bin/sh
# the next line restarts using tclsh \
exec tclsh "$0" "$@"
# デキュー実行後、先頭の要素を削除する
proc enqueue {queueList data} {
upvar $queueList lst
lappend lst $data
}
proc dequeue {queueList} {
upvar $queueList lst
set data [lindex $lst 0] ;# 先頭の要素の取り出し
set lst [lrange $lst 1 end] ;# 先頭の要素を削除
return $data
}
proc checkEmpty {queueList} {
upvar $queueList lst
if {[llength $lst] == 0} {
return 0 ;# 空
} else {
return 1 ;# 有
}
}
## キューのテスト ##
set batch_list ""
enqueue batch_list a1
enqueue batch_list b1
enqueue batch_list c1
enqueue batch_list d1
puts "バッチリスト: $batch_list"
# 空になるまで取り出す
while {[checkEmpty batch_list]} {
puts "バッチ処理 [dequeue batch_list]"
}[実行例]
$ ./queue1.tcl
バッチリスト: a1 b1 c1 d1
バッチ処理 a1
バッチ処理 b1
バッチ処理 c1
バッチ処理 d12.デキュー実行後、先頭の要素は削除せずに、先頭位置を移動させる

head: 要素を取り出す位置。キューの先頭。
tail :要素を追加する位置。キューの末尾+1。
挿入・取り出しが出来る範囲は、 head と tail で囲まれてた部分になります。
このデータ構造を作成する時の要点は
- enqueue を実行すると、tail を+1増やす。
- dequeue を実行すると、head を+1増やす。
- キューの最大値に達すると、それ以上挿入できない。
- tail = head → empty(空)
- tail > Index N(最大値) → full(一杯)。追加できない。
- tail = head かつ tail > Index N → 追加も取り出しもできない。
以下のサンプルは、参照範囲をコントロールする変数が複数あるので、キューに関連する変数をひとまとまりにして、配列で実装しました。
[サンプル] queue2.tcl
#!/bin/sh
# the next line restarts using tclsh \
exec tclsh "$0" "$@"
# 先頭の要素は削除せずに、先頭位置を移動する
# -----------------------------------------------
# キューの実装
# -----------------------------------------------
# キューの作成。デフォルト:100個。
proc Create_Q {queueName {max 100}} {
upvar $queueName Q
set Q(max) [expr $max - 1]
set Q(head) 0
set Q(tail) 0
}
# 挿入
proc Enqueue {queueName data} {
upvar $queueName Q
if {$Q(tail) > $Q(max)} {
puts "このキューは一杯です。"
} else {
set Q($Q(tail)) $data
incr Q(tail)
}
}
# 取り出し
proc Dequeue {queueName} {
upvar $queueName Q
if {$Q(head) == $Q(tail)} {
puts "このキューは空です。"
} else {
set data $Q($Q(head))
incr Q(head)
return $data
}
}
# -----------------------------------------------
# キューのテスト
# -----------------------------------------------
Create_Q batch_list 4 ;# キューの作成。4個作る。
# 挿入
puts "挿入:a1"; Enqueue batch_list a1
puts "挿入:a2"; Enqueue batch_list a2
puts ""
# 取り出し
puts "取り出し:[Dequeue batch_list]"
puts "取り出し:[Dequeue batch_list]"
Dequeue batch_list
puts ""
# 追加
puts "追加:b1"; Enqueue batch_list b1
puts "追加:b2"; Enqueue batch_list b2
Enqueue batch_list b3
puts ""
parray batch_list
[実行例]
$ ./queue2.tcl
挿入:a1
挿入:a2
取り出し:a1
取り出し:a2
このキューは空です。
追加:b1
追加:b2
このキューは一杯です。
batch_list(0) = a1
batch_list(1) = a2
batch_list(2) = b1
batch_list(3) = b2
batch_list(head) = 2
batch_list(max) = 3
batch_list(tail) = 4このキューは、先頭の要素は削除せずに、先頭位置(取り出し位置)と挿入位置が移動するデータ構造をもったキューになります。
キューのテストで「このキューは一杯です。」の後、Dequeueを実行すると最終的に、tail=headかつtail>max の関係になり、追加も取り出しもできない状態になります。
3.リング状のデータ構造を作る。-リングバッファ-
項番2の先頭位置(取り出し位置)と挿入位置がキューの末尾へ向かって移動するデータ構造をもったキューは、データの追加と取り出しを繰り返し実行すると最終的に先頭位置と取出し位置が、配列の末尾を超えてしまうので追加も取り出しも出来なくなります。
また、項番2の構造では、データの取り出しを繰り返す度にキューの先頭部分から空きが出来ることになります。この部分を再利用して回してやれば、効率よくキューを使うことができます。
使い終わったキューの空き部分を再利用するには、項番1のように、デキュー実行後、先頭の要素を削除する方法が考えられます。しかし、この方法は、配列のように各要素が別々の箱の構造をしている場合、デキュー実行の度に先頭方向へ各要素をシフトさせる処理が必要になります。
このようなことから、配列によるキューの実装では、項番1のような方法は取らずにtailまたはheadの位置がキューの一番後ろに到達すると、この位置をキューの先頭へ繋げて位置をループさせます。このリング状の形をしたデータ構造のことをリングバッファ(ring buffer)といいます。
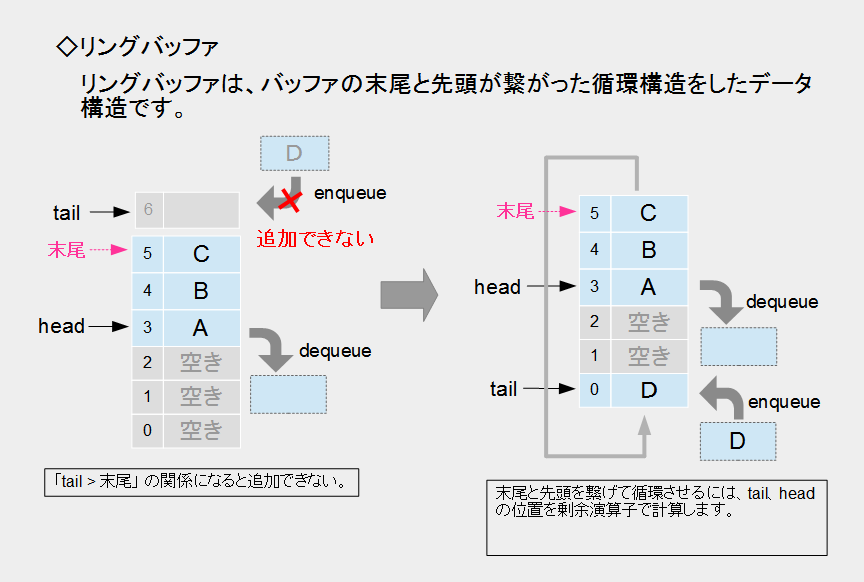
末尾と先頭を繋げてリングを循環させるには、tailとheadの位置を剰余演算子を使って計算します。
例えば、剰余演算子を使って、n % 3 を計算すると、
nが0から5の数字の場合
0 % 3 = 0
1 % 3 = 1
2 % 3 = 2
3 % 3 = 0
4 % 3 = 1
5 % 3 = 2
余りは、0, 1, 2, 0, 1, 2 となり、余りが循環します。
これを利用してキューを循環させます。

キューのサイズ3個の場合
- head = tail 時はempty。
- tail(挿入位置)の計算は?
要素を追加後、以下の計算式で next tail を求める。
(tail + 1) % 3 = 次の挿入位置
1 % 3 = 1
2 % 3 = 2
3 % 3 = 0 → 配列の先頭に戻ります。
- head(取出し位置)も同じ要領で計算します。
ここで問題が発生!
一列に並べた構造をしたキューの場合、要素が全て埋まった状態(full)になると、次の挿入位置は以下の関係でした。
tail > Index N(最大値) → full(一杯)
リングバッファの場合は以下の関係になります。
head = tail
この状態は、emptyの状態でもあり、空(カラ)なのか一杯なのか判別できません。
古いデータから上書きするような用途であれば、これでもいいかもしれませんが、上書きしない用途であれば、空(カラ)なのか一杯なのか判別する必要があります。
この問題を解決する方法として以下の2つの方法が考えられます。
- キューが空であることを示すフラグを作る。
- tailとheadの間には、常に空きの要素を1つ以上残るようにして、キューが一杯になってもhead = tail の関係にならないようにする。(tail+1 = head の関係になるとfull)
以下のサンプルは、2つ目の方法をTclで実装した例です。
キューのサイズが1つ減るので、指定サイズ+1の容量を確保するようにしています。
[サンプル] queue3.tcl
#!/bin/sh
# the next line restarts using tclsh \
exec tclsh "$0" "$@"
# リング状のデータ構造を作る。-リングバッファ-
# -----------------------------------------------
# キューの実装
# -----------------------------------------------
# キューの作成
proc Create_Q {queueName {max 100}} {
upvar $queueName Q
set Q(max) [expr $max + 1] ;# 要素数+1
set Q(head) 0
set Q(tail) 0
}
# 挿入
proc Enqueue {queueName data} {
upvar $queueName Q
if {($Q(tail) + 1) % $Q(max) == $Q(head)} {
puts "このキューは一杯です。"
} else {
set Q($Q(tail)) $data
set Q(tail) [expr ($Q(tail) + 1) % $Q(max)]
}
}
# 取り出し
proc Dequeue {queueName} {
upvar $queueName Q
if {$Q(head) == $Q(tail)} {
puts "このキューは空です。"
} else {
set tmp $Q($Q(head))
set Q(head) [expr ($Q(head) + 1) % $Q(max)]
return $tmp
}
}
# -----------------------------------------------
# キューのテスト
# -----------------------------------------------
Create_Q batch_list 4 ;# 要素数4個のキューを作成
# 挿入
puts "挿入:a1"; Enqueue batch_list a1
puts "挿入:a2"; Enqueue batch_list a2
puts ""
# 取り出し
puts "取り出し:[Dequeue batch_list]"
puts "取り出し:[Dequeue batch_list]"
Dequeue batch_list
puts ""
# 追加
puts "追加:b1"; Enqueue batch_list b1
puts "追加:b2"; Enqueue batch_list b2
puts "追加:b3"; Enqueue batch_list b3
puts "追加:b4"; Enqueue batch_list b4
Enqueue batch_list b5
puts ""
# 取り出し
puts "取り出し:[Dequeue batch_list]"
puts "取り出し:[Dequeue batch_list]"
# 追加
puts "追加:c1"; Enqueue batch_list c1
puts ""
parray batch_list[実行例]
$ ./queue3.tcl
挿入:a1
挿入:a2
取り出し:a1
取り出し:a2
このキューは空です。
追加:b1
追加:b2
追加:b3
追加:b4
このキューは一杯です。
取り出し:b1
取り出し:b2
追加:c1
batch_list(0) = b4
batch_list(1) = c1
batch_list(2) = b1 ← 現在のtailの位置
batch_list(3) = b2 ← 現在の空間の位置
batch_list(4) = b3 ← 現在のheadの位置
batch_list(head) = 4
batch_list(max) = 5
batch_list(tail) = 2